Abstract
We introduce a new approach for generating realistic 3D models with UV maps through a representation termed "Object Images." This approach encapsulates surface geometry, appearance, and patch structures within a 64x64 pixel image, effectively converting complex 3D shapes into a more manageable 2D format. By doing so, we address the challenges of both geometric and semantic irregularity inherent in polygonal meshes. This method allows us to use image generation models, such as Diffusion Transformers, directly for 3D shape generation. Evaluated on the ABO dataset, our generated shapes with patch structures achieve point cloud FID comparable to recent 3D generative models, while naturally supporting PBR material generation.
Motivation
Recently, 3D generative models have shown impressive results in synthesizing 3D objects. However, many of the current 3D generative models treat 3D shapes as a "statue" like objects. In contrary to the many high-quality human-made 3D assets which contains rich geometric and semantically meaningful patches, the statue-like objects are difficult to edit, animate and interact with. For example, the headphone shown below has intricate geometric parts that its "statue" version does not capture. Also, on the right example the pack of books consists of multiple books standing closely to each other, which is very difficult to separate through current single-view reconstruction techniques.
The core challenge to generate 3D shapes with proper geometric connectivity and semantic part structures is the irregularity of these properties, since most recent techinques require regular, tensorial input. We find that these irregularities can be effectively handled through packing the geometry, patch structures and material into an image format, which we term as "Object Images" or "omages" (A kind of Multi-Chart Geometry Images). In this work, we explore to use image diffusion model to generate low-resolution omages to show this paradigm of 3D generation is possible. For more details, please refer to our paper.
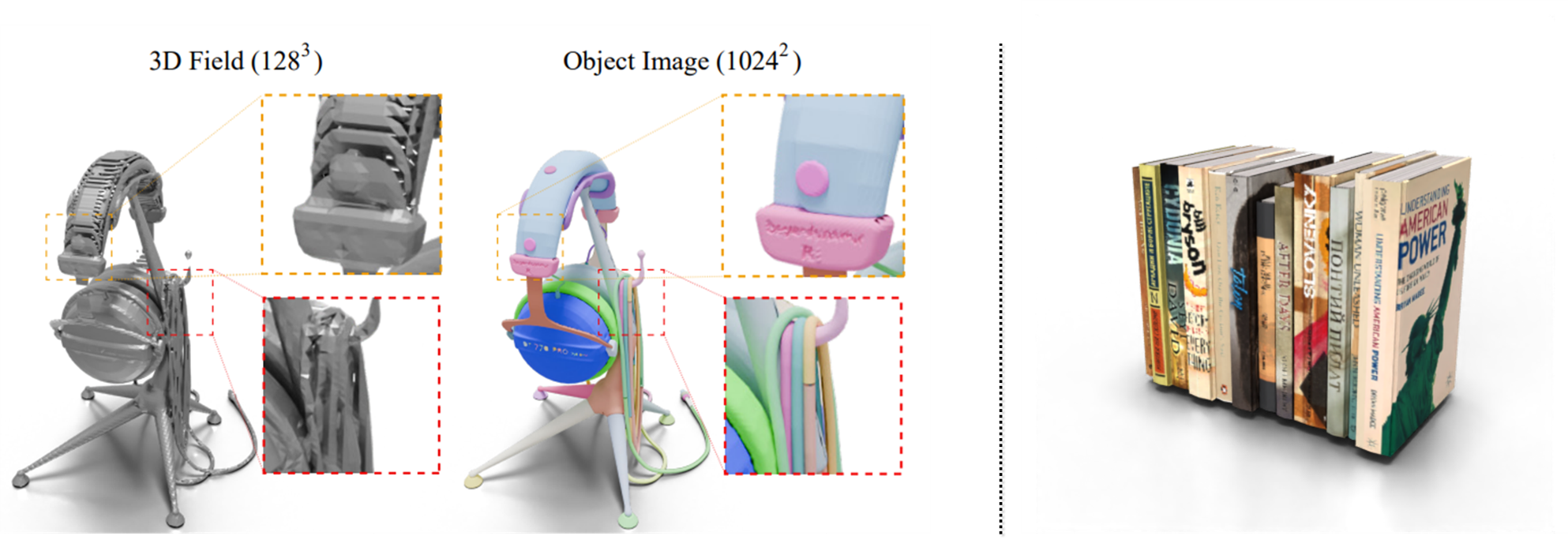
Method
We first preprocess the UV-unwrapped 3D shapes into 1024x1024 omages and then downsample it with special care to 64x64 omages. Then we just flatten the omage into a sequence and learn their distribution through a Diffusion Transformer (DiT) of patch size 1. The motivation of using DiT is that we observe the generation of omages is essentially image generation and set generation combined. A very cool thing is that during the denoising process, discrete structures emerge out of the continuous image format, and the generated results exhibit great variety in the number and size of patches.

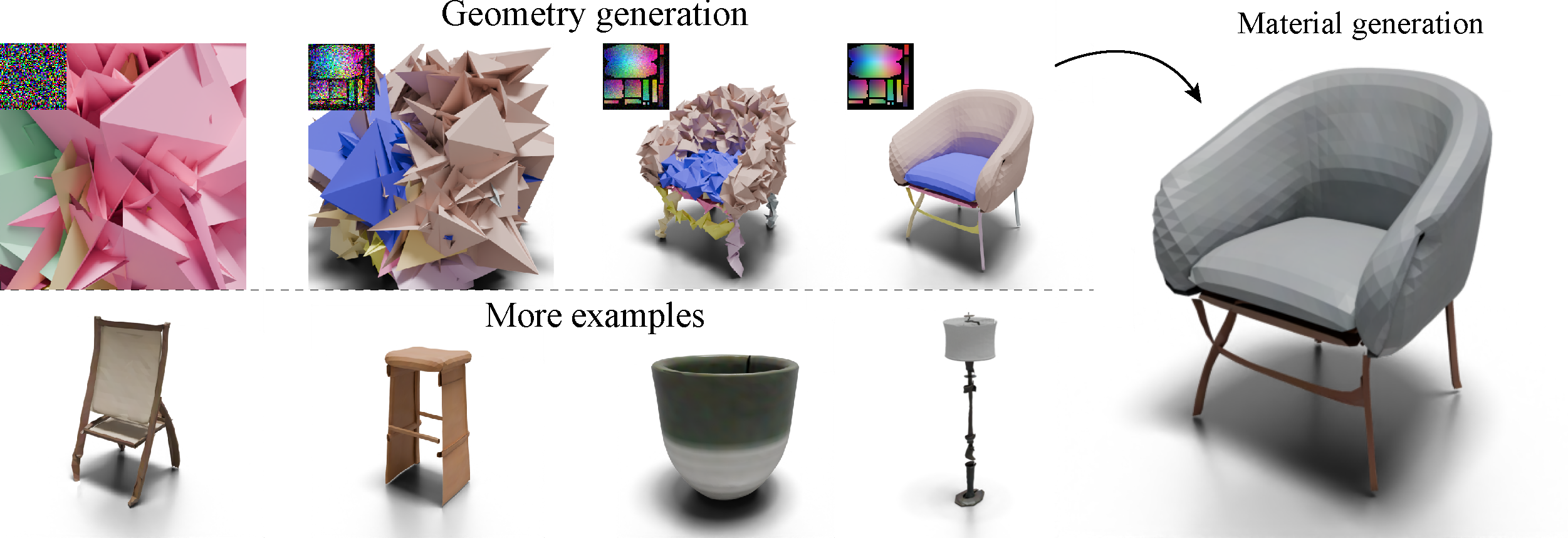
More results samples
Here we show some more results of our model trained on the ABO dataset. Although there are gaps between the patches, the overall alignment of the patches demonstrate the potential of this 3D generation paradigm. We also show the potential of our model to generate objects with PBR materials, like mirrors.

Takeaways
1. Omage encodes geometry as a (R,R,3+1) image, which is essentially a 16-bit RGBA PNG!
2. PBR material is encoded in another (R,R,8) image. So three PNGs will give you a realistic 3D object.
3. You can use image generation models to generate 3D objects, one image for one object!
4. Discrete patch structures emerge out of continuous noise during the denoising process.
5. Patch segmentation comes naturally from 2D disconnected components, no instance labels needed!
6. Irregular connectivity & complex topology? No worries, all encoded in a regular image.
7. Change your object resolution by just rescaling the omage!
8. Generated shapes come with UV maps—no unwrapping required.
X. And there’s even more to discover!
BibTeX
@misc{yan2024omages64,
title={An Object is Worth 64x64 Pixels: Generating 3D Object via Image Diffusion},
author={Xingguang Yan and Han-Hung Lee and Ziyu Wan and Angel X. Chang},
year={2024},
eprint={2408.03178},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2408.03178},
}